J. Heaton class chapter 8.2, "Evaluating Feature Importance"
"More important inputs will produce a less accuratescore when they are removed by shuffling them."
The function perturbation_rank() works as follows:
- shuffle each input column
- compute the prediction
- compute the error as log_loss between prediction and actual y values.
The following table shows the difference between prediction and y in each case:
sl
sw
pl
pw
0
0
-1
1
0
0
1
0
0
0
0
0
1
0
0
0
0
0
0
0
0
0
1
0
0
0
-1
0
0
0
-1
0
0
0
0
0
0
0
-1
0
0
0
-2
0
0
0
0
0
0
0
1
0
0
0
2
1
0
0
1
0
0
1
-1
0
0
0
0
0
0
0
-1
0
0
0
1
1
0
0
-1
0
0
0
1
0
0
0
-1
-1
0
0
0
0
0
0
0
-1
0
0
-2
-1
0
0
0
-1
0
0
-2
-1
0
0
0
-1
0
0
1
0
0
0
1
1
0
0
0
0
0
0
0
0
0
0
1
0
0
0
2
0
0
0
0
0
0
0
-1
-1
0
0
0
0
0
0
1
0
It is apparent that the column petal_l has far more errors than the other columns, therefore it is regarded as
more important.
May 14, 2025
The code in the chapter "Biological Response with Neural Network" in module 8 part 2 does not run, giving the
error:
ModuleNotFoundError: No module named 'tensorflow.keras.wrappers'
Brave search "ModuleNotFoundError: No module named 'tensorflow.keras.wrappers'",
AI recommends two options:
"As of TensorFlow 2.15, the wrappers submodule under tensorflow.keras has been removed. To resolve this issue,
you can either uninstall the current version of TensorFlow and install an earlier version where the wrappers
submodule is still available,"
Attempt 1
pip install scikeras
in the existing jh_class environment failed.
failed
Brave search "proba returns two values":
The predict_proba function in scikit-learn returns an array where each row corresponds to a sample and each
column corresponds to a class probability. When there are two classes, the function returns a 2-column array,
where the first column represents the probability of the sample belonging to the first class, and the second
column represents the probability of the sample belonging to the second class.
Example:
[0.3 0.7 ]
[0.68 0.32]
[0.47 0.53]
For the first sample, the probability for the first class is 30%, and for the second class it is 70%.
Where is the source code for the function predict_proba() ?
Open terminal.
cd ~/miniconda3/envs/ensemble/lib/python3.7
grep -r "def predict_proba("
This is the function that is called when the model is Sequential().
Deprecation warning
Brave search "kera api predict_proba":
"this function has been deprecated in Tensorflow version 2.6 and later versions of Keras. Instead, you should
use the predict() function directly to achieve similar results."
May 16, 2025
Structure of class_08_2_keras_ensembles_bio_blend.py
main program
The file bio_train.csv contains the training data.
It contains and 3751 rows and 1777 columns.
The first column named "activity" is the target.
All the other columns are the predictors.
The predictor values are read into the variable x and it is of shape (3751, 1776)
The target values are read into the variable y and it is of shape (3751,)
The file bio_test.csv contains the data for which a prediction will be made.
It contains and 2501 rows and 1776 columns.
Since it is meant for the Kaggle submission, it does not contain the target
column ("solution")
The predictor values for the submission are read into the variable x_submit and it is of shape (2501,
1776)
The blend_ensemble(x, y, x_submit) is called and it returns the variable submit_data which is of shape (2501,
2).
The values in submit_data are then stretched such that the smallest value becomes 0 and the largest value
becomes 1.
Finally, an index column and the column 1 (second column) of submit_data are provided with the labels
"MoleculeId" and "PredictedProbability" and saved to the submission file named "submit.csv".
May 18, 2025
blend_ensemble() function
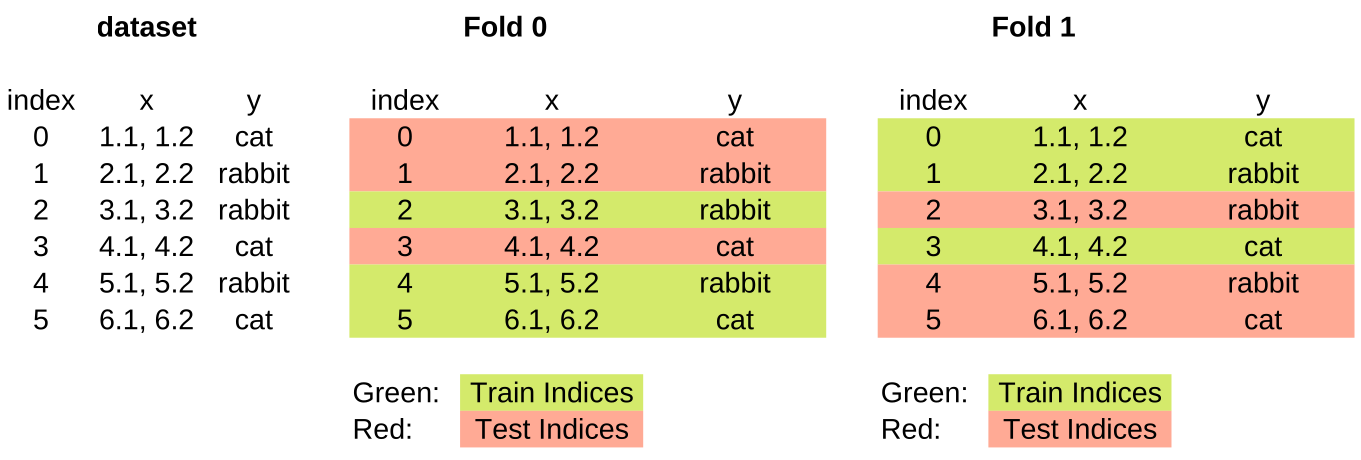
The blend_ensemble() function starts by generating the indices for a stratified KFold.
Use
KFold When dealing with a regression problem.
StratifiedKFold When dealing with a classification problem.
Use of a Stratified KFold with a single model
The function
kf.split(x,y)
simply generates indices for the elements of the dataset.
Each fold contains the indices of all elements, just in different variations.
The blend_ensemble() function receives the parameters x,y, and x_submit and creates a stratified K-Fold with the
parameters for the predictors and targets from the file bio_train.csv.
folds = list(kf.split(x, y))
The list() function converts the folds into an array of the folds.
The program then creates an array of various models.
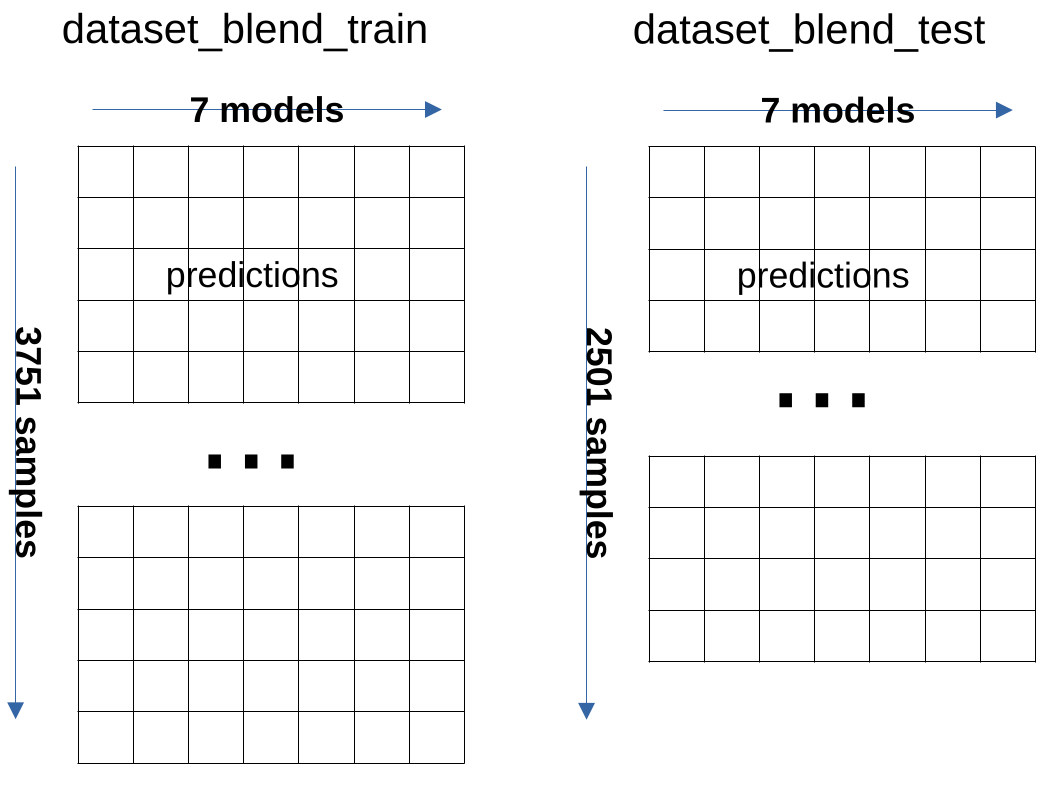
Two new variables dataset_blend_train and dataset_blend_test are created
to hold the predictions for later blending:
dataset_blend_train is of shape (3751,7)
- 3751 is the number of rows in the training and 7 is the number of models
dataset_blend_test is of shape (2501,7)
- 2501 is the number of rows in the submit data and 7 is the number of models
May 20, 2025
blend_ensemble() function continued
The code then contains a nested loop:
- the outer loop iterates over the 7 models
- the inner loop iterates over the 10 folds.
The outer loop begins by creating the variable named fold_sums which is of shape (3751,10).
The columns of this variable will be filled in the inner loop with values that pertain to the submit
dataset.
In the inner loop, the predictors for training and testing are read into the variables x_train and x_test,
using the indices of each according fold.
Since the number of folds is 10, x_train will have 3376 rows and x_test will have 375 rows.
3376+375=3751
The target values are read into the variables y_train and y_test in an equivalent manner.
Then the model (which is selected in the outer loop from 7 models) is trained.
The predictions for x_test are stored in the variable named pred.
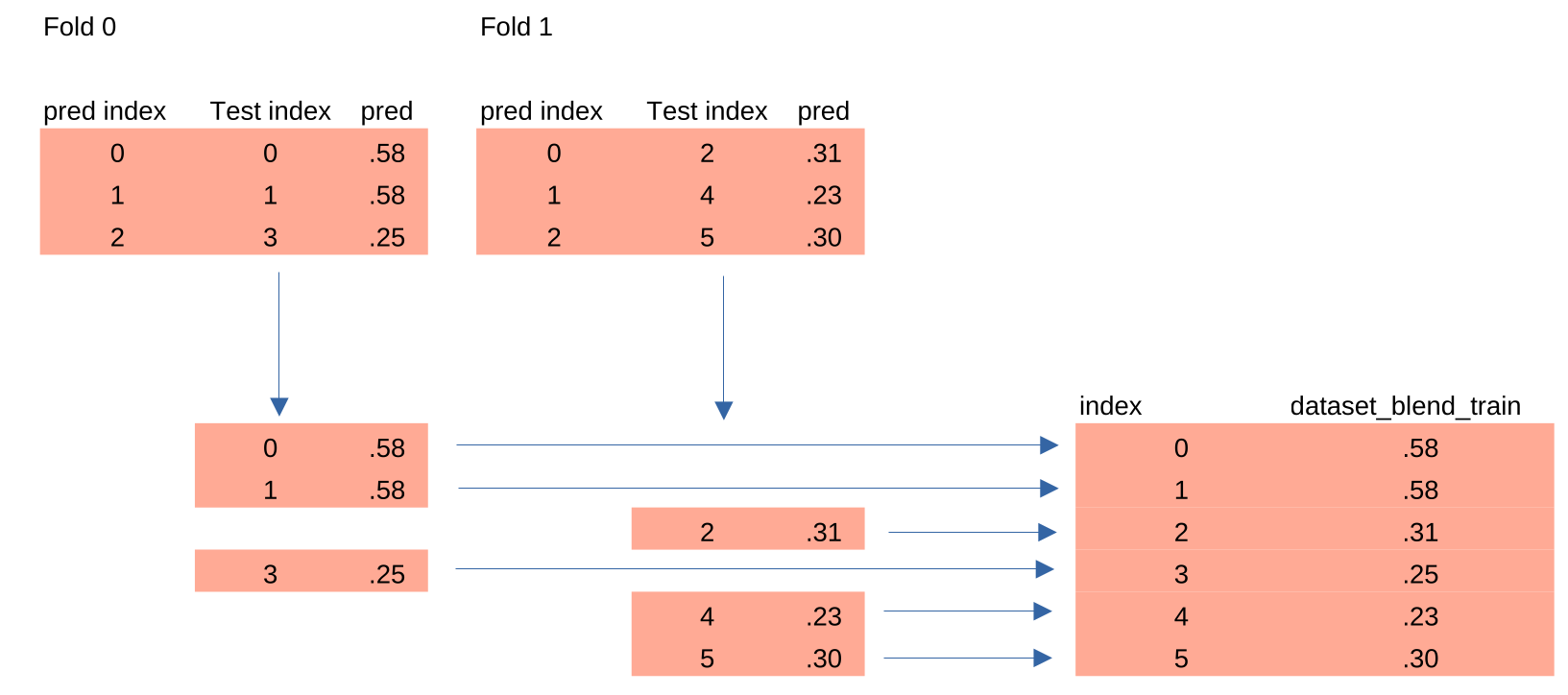
The following line fills up the (3751,7) array named dataset_blend_train with the predictions for each
model (j is the loop variable for the models):
dataset_blend_train[test, j] = pred[:, 1]
Because we are working with 10 folds, we only get 375 values in each fold iteration.
(376 values in the first fold because 3751 doesn't divide by ten)
Each prediction is placed in the correct row in dataset_blend_train by making use of the indices that are stored
in the test variable.
Simplified Example:
The animation shows how the predictions are placed in the correct locations in the dataset_blend_train
variable:
May 23, 2025
blend_ensemble() function continued
The model is used again to compute the predictions for the submit dataset.
The predicitions are stored in the pred2 variable.
For each fold in the current model, the predicitions are saved in the fold_sums variable.
After the loop for the folds has completed, we end up with a fold_sums variable that contains the predictions
for the submit inputs, for each of the ten folds.
The code now computes the mean value for each row in the fold_sums variable and stores it in the according
column of the dataset_blend_test variable.
At the end of the nested loop, we have two variables containing predictions:
where the predictions in dataset_blend_train originated from the training data,
and the predictions in dataset_blend_test originated from the submit data.
The final step is the blending of the models.
The code uses Logistic Regression (from scikit-learn) to blend the models in order to get a better prediction
out of the training data.