February 9, 2025
How does model.evaluate() calculate the accuracy in the Brownlee example?
https://machinelearningmastery.com/how-to-develop-a-generative-adversarial-network-for-a-1-dimensional-function-from-scratch-in-keras/
During training, we told the trainer that a real sample has a target value of 1 and a fake sample has a target
value of 0.
The model.predict value that is fed with the values from a training epoch will return a value p
- 0 < p < 0.5 for a fake input
- 0.5 < p < 1 for a real input
When we feed the model.predict function with the part of input data that are real samples and count the
predicted values that are between 0.5 and 1, and divide that number by the number of total real samples in that
epoch, we get the accuracy.
Example:
Output for epoch 0
epoch 0 acc_real 0.609 acc_fake 0.172
predicted real samples= 39 total real samples= 64 accuracy= 0.609375
February 14, 2025
YOLOv5 (you only look once version 5) creates a configuration file named settings.json located at
~/.config/ultralytics/settings.json
One of the entries is "datasets_dir"
and it contains the location of the datasets.
If upon calling Yolo no dataset location is specified, then yolo will use this entry.
February 15, 2025
Data Folder Structure in YOLO
https://medium.com/@manasnandmohan/data-folder-structure-in-yolo-d335a05f6553
"Split your directory automatically to train, validation & test folders"
https://www.kaggle.com/discussions/general/321868
The Statefarm Kaggle example
https://www.kaggle.com/code/sayedgamal99/in-cabin-state-farm-distracted-driver-detection
uses splitfolders() to generate the folder structure required by YOLO.
The downloaded zip file contains two folders: test and train.
The test folder is not used, the train folder contains 0 folders according to classification.
The function splitfolders()
splitfolders.ratio(sourcefoldername, output=datasetfoldername, seed=32, ratio=(0.7, 0.15, 0.15))
splits the data from train to dataset into three folders, each with its 10 subfolders, according to
classification:
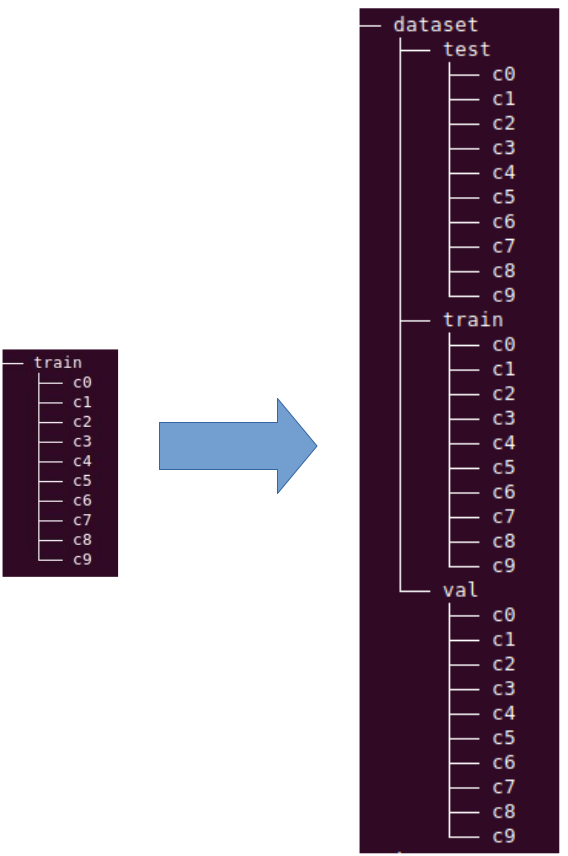
Organizing folders in this manner allows calling the YOLO train function to find the data
model = YOLO('yolo11s-cls.pt')
model.train(data = datasetfoldername,..)


